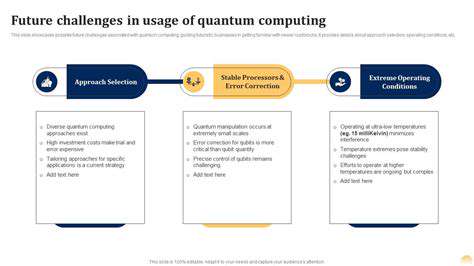
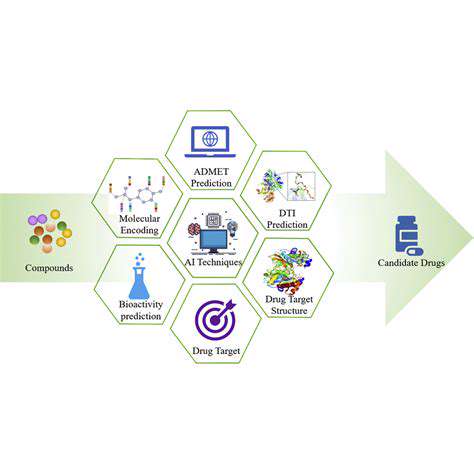
AI's Role in Identifying Molecular Targets
AI's Potential in Drug Discovery
Artificial intelligence (AI) is rapidly transforming various sectors, and drug discovery is no exception. AI algorithms can analyze vast datasets of molecular structures and biological information, accelerating the identification of potential drug candidates. This process, previously reliant on laborious manual screening, can now be significantly accelerated and optimized by AI's ability to identify patterns and relationships that might be missed by human researchers.
By leveraging machine learning techniques, AI can sift through millions of compounds, identifying those with the highest probability of binding to specific targets within the body. This accelerates the initial screening phase, allowing researchers to focus on the most promising leads and potentially reducing the time and resources required for drug development.
Molecular Structure Analysis
AI excels at analyzing the intricate three-dimensional structures of molecules. This analysis allows researchers to understand how molecules interact with each other and with biological targets. Understanding these interactions is crucial for designing effective drugs that can target specific molecular mechanisms within the body.
The ability to accurately predict molecular interactions is a significant advantage in drug discovery. AI models can predict the binding affinities of molecules to proteins, enzymes, and other biological targets, providing valuable insights into their potential therapeutic effects.
Identifying Potential Drug Targets
AI algorithms can sift through vast genomic and proteomic data to identify potential drug targets. These targets are specific molecules within the body that, when modified, can influence disease processes. Identifying these targets is a crucial first step in the drug discovery process.
AI can analyze data from various sources, including clinical trials, research papers, and databases of molecular information, to identify potential drug targets with high accuracy and efficiency. This process often involves complex pattern recognition and machine learning techniques.
Predicting Drug Efficacy and Toxicity
AI plays a vital role in predicting the efficacy and toxicity of potential drug candidates. By analyzing various factors such as molecular structure, binding affinities, and interactions with biological systems, AI can estimate the likelihood of a drug having a desired therapeutic effect and potential side effects.
This prediction capability is crucial for reducing the risk of adverse effects and improving the overall safety profile of new drugs. Early predictions can help researchers prioritize candidates with favorable profiles, saving time and resources.
Accelerating the Drug Development Process
AI has the potential to significantly streamline the drug development process by automating various tasks and accelerating the identification of promising candidates. This automation frees up researchers to focus on more complex aspects of the process, such as designing clinical trials and interpreting experimental results.
Reducing the time and cost associated with drug development is a significant benefit of AI integration. A faster development process can lead to more effective treatments becoming available to patients sooner.
Improving Target Identification Accuracy
AI's ability to analyze complex datasets allows for more accurate target identification compared to traditional methods. This increased accuracy in pinpointing the specific molecular targets for disease is critical in developing effective therapies.
Traditional methods often rely on limited data and simplified models. AI models, on the other hand, can incorporate vast amounts of data, including various types of molecular information and experimental results, leading to more robust and accurate predictions.
Improving the Efficiency of Experiment Design
AI can be used to optimize the design of experiments in drug discovery. By predicting the outcomes of various experimental scenarios, AI can guide researchers towards the most informative and efficient experimental approaches.
This optimization can significantly reduce the time and resources required for experimentation, enabling researchers to identify promising candidates more quickly. This ultimately accelerates the overall drug development process.
Predictive Modeling for Treatment Response
Understanding the Fundamentals of Predictive Modeling
Predictive modeling in the context of cancer treatment response utilizes various algorithms and statistical techniques to forecast how a patient will react to a particular therapy. This process leverages historical data, including patient demographics, tumor characteristics, genetic profiles, and prior treatment experiences, to build predictive models. These models then estimate the probability of a specific treatment being effective for a given patient, ultimately guiding treatment decisions and improving outcomes.
Essentially, predictive modeling aims to identify patterns and relationships within the data that can be used to anticipate the likelihood of success or failure of a treatment approach. This is crucial in precision oncology, where personalized treatment strategies are paramount.
Data Sources for Predictive Modeling
A wide range of data sources are critical for constructing robust predictive models. These include patient medical records, genomic sequencing data, imaging studies (like CT scans and MRIs), and even lifestyle factors. Integrating diverse data types allows for a more comprehensive understanding of the patient's unique characteristics and potential response to treatment.
The quality and completeness of the data are paramount. Missing or inaccurate data can lead to unreliable models and ultimately, suboptimal treatment decisions. Rigorous data validation and cleaning procedures are essential for building trust in the predictive models.
Key Algorithms in Predictive Modeling
Several machine learning algorithms are frequently employed in predictive modeling for cancer treatment response. These include support vector machines, random forests, and neural networks. Support vector machines excel at identifying patterns in high-dimensional data, while random forests offer robust performance and handle complex relationships. Neural networks, with their ability to learn intricate patterns, are increasingly used for their potential to capture more complex interactions within the data.
Challenges in Predictive Modeling
Despite the potential benefits, predictive modeling in oncology faces significant hurdles. One major challenge is the complexity of the disease itself – cancer is not a single entity, but rather a diverse collection of diseases with varied genetic and biological characteristics. This complexity makes it challenging to develop universally applicable predictive models.
Another challenge lies in the availability and quality of data. Gathering and integrating diverse datasets across various institutions can be time-consuming and resource-intensive. Furthermore, ensuring data privacy and security is a critical ethical consideration.
Validation and Refinement of Models
Developing accurate predictive models requires rigorous validation and refinement. This involves splitting the data into training, testing, and validation sets. The model's performance on the testing set is evaluated to assess its generalizability to new patients. The validation set is used to fine-tune the model to optimize its predictive accuracy.
Continuous monitoring and updating of the models are crucial. As new data becomes available and our understanding of cancer biology evolves, the models need to be adapted and refined to maintain their predictive accuracy and relevance.
Clinical Applications and Implications
Successful predictive modeling has the potential to revolutionize cancer treatment. By identifying patients most likely to benefit from specific therapies, oncologists can personalize treatment plans and improve outcomes. This leads to more effective use of resources and reduced adverse effects for patients.
Ultimately, integrating predictive modeling into clinical practice could dramatically shift the paradigm from a one-size-fits-all approach to a more tailored and individualized approach to cancer care, potentially increasing the efficacy and reducing the toxicity of treatment regimens.
Ethical Considerations in Predictive Modeling
The use of predictive models in clinical decision-making raises important ethical considerations. Ensuring fairness and avoiding bias in the models is paramount. The potential for misinterpretation or misuse of the results must be carefully considered. Transparent communication of the limitations and uncertainties of the models is essential to avoid over-reliance on their predictions.
These ethical considerations must be addressed proactively to ensure that predictive modeling is used responsibly and ethically, ultimately benefiting patients and fostering trust in the medical field.