Image Manipulation
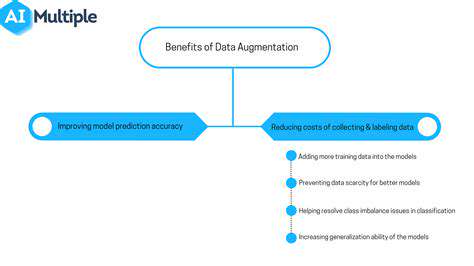
Image data augmentation techniques are crucial for improving the performance of machine learning models, especially when dealing with limited training data. These techniques involve creating synthetic variations of existing images, effectively expanding the dataset without collecting new data. This process can significantly enhance the model's ability to generalize to unseen data and improve its robustness against noise and variations in the real-world data. For example, techniques like rotation, flipping, cropping, and color jittering can introduce diverse perspectives and lighting conditions, enabling the model to learn more robust features.
One popular image augmentation technique is random cropping. This involves selecting a random portion of the image and resizing it to the original dimensions. This method introduces variations in the object's location within the image, forcing the model to learn features regardless of the object's position. Another important augmentation technique is color jittering, which randomly adjusts the brightness, contrast, saturation, and hue of the image. This helps the model to be less sensitive to variations in lighting conditions and improve its performance in different lighting environments.
Data Augmentation Techniques: Textual Data
Data augmentation for textual data differs significantly from image augmentation, as text data doesn't have visual attributes. Common techniques for text augmentation include back-translation, synonym replacement, and random insertion/deletion of words. Back-translation involves translating the text to another language and then translating it back to the original language, introducing subtle variations and improving the model's understanding of nuances in the text.
Synonym replacement involves replacing words with their synonyms, maintaining the overall meaning of the sentence while introducing diversity. This method can help the model learn contextual relationships between words and improve its understanding of sentence structure. Random insertion and deletion of words can also be effective, as it introduces noise and helps the model learn to handle missing or extra information in the text. These techniques are particularly important for tasks like sentiment analysis and text classification, where the model needs to be robust against variations in language use.
Data Augmentation Techniques: Audio Data
Audio data augmentation techniques are employed to enhance the robustness and generalization ability of models trained on audio data. Techniques such as time stretching, pitch shifting, and adding noise can create synthetic audio variations that represent different real-world conditions. Time stretching, for example, simulates variations in the speed at which audio is played, while pitch shifting changes the perceived tone of the audio.
Adding noise to audio data can simulate background sounds or environmental factors, making the model more resilient to these real-world factors. These techniques are particularly useful for applications like speech recognition and music classification, where audio signals can be affected by various environmental factors and conditions. These methods are key to developing models that can accurately process audio in diverse and challenging settings.
Low-carb diets, encompassing a wide range of approaches, fundamentally restrict carbohydrate intake. This restriction, while often perceived as a simple dietary change, has profound effects on metabolism and overall health. The core principle revolves around shifting your body's primary fuel source from carbohydrates to fats. This metabolic shift can lead to various benefits, including weight management, improved blood sugar control, and potentially enhanced energy levels. However, it's crucial to approach any dietary change thoughtfully and understand the potential implications for both short-term and long-term well-being. A holistic approach considers not just the immediate impact on weight but also the broader effect on overall health and lifestyle.