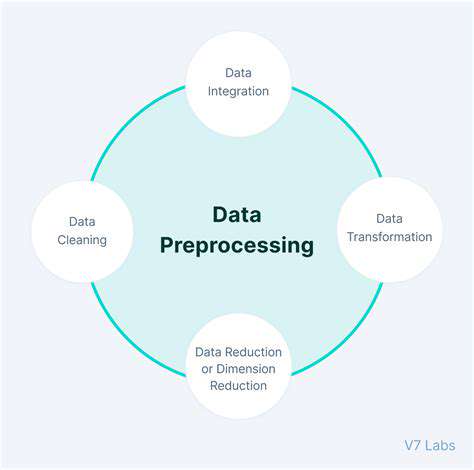
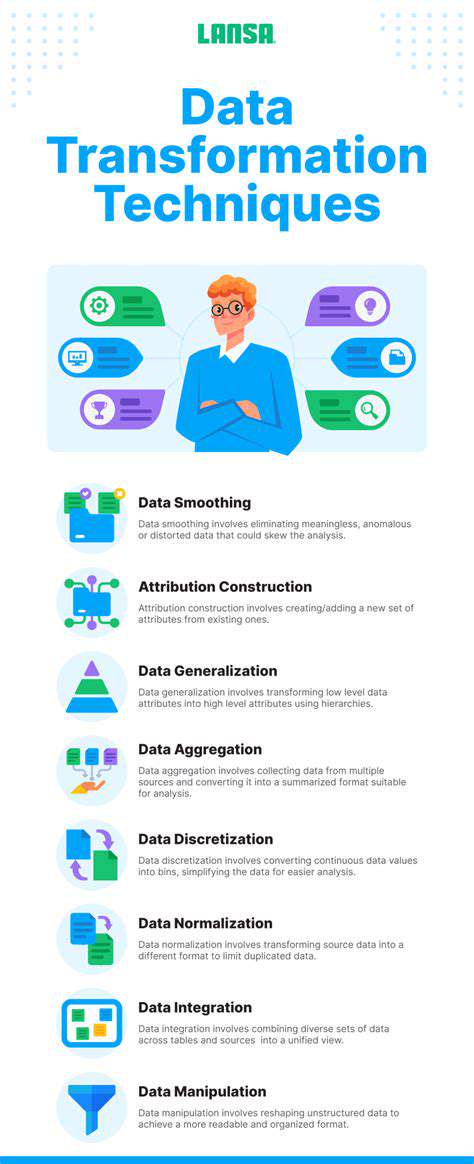
Data Transformation Techniques
Data Cleaning
Data cleaning is a crucial initial step in any data analysis project. It involves identifying and correcting or removing inaccurate, incomplete, or inconsistent data points. This process ensures that the data is reliable and suitable for further analysis. Cleaning techniques often include handling missing values, correcting errors, and standardizing formats. Thorough data cleaning can significantly impact the quality and accuracy of results.
A common example of data cleaning is handling missing values. These missing values can arise due to various reasons, such as data entry errors or equipment malfunctions. Methods for handling missing values include imputation, deletion, or using advanced statistical techniques. Careful consideration of the appropriate method is essential, as it can influence the subsequent analysis.
Data Integration
Data integration combines data from multiple sources into a unified dataset. This process allows for a more comprehensive understanding of the information by bringing together disparate data points. This consolidation is essential for businesses to gain a holistic view of their operations and customers. Data integration techniques can vary from simple merging to complex ETL (Extract, Transform, Load) processes, each with its own set of considerations.
Effective data integration requires careful planning and execution. Key considerations include data quality, format compatibility, and the identification of common attributes across different sources. This process ensures that the integrated data reflects a unified view of the information, fostering a comprehensive understanding.
Data Transformation
Data transformation is the process of converting data from one format to another to improve its usability and suitability for analysis. This might involve changing data types, converting units of measurement, or restructuring data into a more suitable format. For example, transforming raw sales data into a format suitable for creating sales reports.
Transformation techniques often involve using scripting languages like Python or R, which allow for more complex and customized transformations. These techniques enable flexibility and adaptability in dealing with different types of data and analysis needs. Furthermore, data transformations can involve aggregation, normalization, or standardization, each with a specific impact on the data.
Data Reduction
Data reduction techniques aim to simplify large datasets by reducing the amount of data while preserving essential information. This process is particularly useful when dealing with extremely large datasets, as it can significantly improve processing time and resource utilization during analysis. Common techniques include dimensionality reduction, aggregation, and summarization.
Dimensionality reduction methods, such as Principal Component Analysis (PCA), can reduce the number of variables in a dataset while retaining most of the variance. This can be crucial for building predictive models or visualizing complex data relationships. Data reduction is an important step for improving efficiency and enabling more effective analysis, especially with big datasets. It helps to improve the speed and efficiency of analytical processes.
Outlier Detection and Handling
Outlier Detection Methods
Identifying outliers is a crucial step in data preprocessing for machine learning. Outliers are data points that significantly deviate from the rest of the data, potentially skewing statistical analyses and impacting the performance of machine learning models. Various methods exist for detecting outliers, ranging from simple visual inspection to sophisticated statistical techniques. Understanding the nature of your data and the characteristics of potential outliers is essential for choosing the most appropriate detection method.
Common outlier detection methods include box plots, scatter plots, Z-score calculations, and interquartile range (IQR) analysis. Box plots visually represent the distribution of data, highlighting potential outliers as points outside the whiskers. Scatter plots can reveal relationships between variables and identify data points that don't fit the general trend. Z-scores measure how many standard deviations a data point is from the mean, allowing for the identification of extreme values. IQR methods define a range around the interquartile range, flagging data points falling outside this range as outliers. The choice of method will depend on the specific dataset and the nature of the outliers expected.
Handling Outliers
Once outliers are detected, the next step is to decide how to handle them. Simply removing outliers can lead to data loss, but inappropriately retaining them can negatively affect model performance. Strategies for handling outliers include removal, transformation, or the use of robust statistical methods. Removing outliers might be appropriate if they are clearly errors or if the dataset is large enough to tolerate the loss of a few data points. However, careful consideration is needed to avoid introducing bias or losing valuable information.
Transforming the data, such as using logarithmic or square root transformations, can often mitigate the impact of outliers. Robust statistical methods, such as using the median instead of the mean, can also reduce the influence of outliers. The best approach depends on the specific dataset, the characteristics of the outliers, and the machine learning model being used. Often, exploratory data analysis plays a key role in determining the most suitable handling strategy.
Impact of Outliers on Machine Learning Models
Outliers can significantly influence the performance of machine learning models. Linear regression models, for instance, are particularly sensitive to outliers, as they can disproportionately affect the estimated coefficients. Classification models, such as logistic regression, may also exhibit reduced accuracy when outliers are present. Clustering algorithms, aiming to group similar data points, can be significantly affected by outliers, potentially leading to inaccurate or misleading clusters. Outliers can lead to unreliable model predictions and inaccurate estimations, ultimately impacting the overall performance and reliability of the machine learning pipeline.
The impact of outliers depends heavily on the specific model and the nature of the data. A thorough understanding of the potential impact on different models is crucial when dealing with outliers in a machine learning project. This understanding guides the choice of outlier detection and handling techniques, ensuring that the machine learning model is robust and generalizable.
Preprocessing Strategies for Different Data Types
The best approach to handling outliers varies depending on the type of data being analyzed. For numerical data, techniques like Z-score or IQR methods can be effective. In categorical data, identifying and handling outliers often involves examining the frequency distribution of categories and considering whether categories are infrequent or errors. For time series data, outliers might manifest as unusual spikes or drops in values. The methods for detecting and handling these outliers in time series might differ from those used for other data types. An understanding of the specific characteristics of each data type is essential for choosing the most appropriate preprocessing steps.
Careful consideration of the data type is essential for effective outlier handling. Appropriate preprocessing steps can lead to more reliable and accurate models. A lack of attention to the specific characteristics of different data types can result in inappropriate or ineffective outlier handling methods, negatively impacting the performance and reliability of the machine learning model.