Machine Learning Algorithms for Prognosis

Supervised Learning Algorithms
Supervised learning algorithms are a crucial part of machine learning, where the algorithm learns from a labeled dataset. This means that each data point in the dataset is associated with a known output or target variable. The algorithm's goal is to learn a mapping function that can accurately predict the output for new, unseen data points. Examples include linear regression, logistic regression, and support vector machines. These algorithms are widely used in various applications, such as image recognition, spam detection, and medical diagnosis.
In supervised learning, the algorithm learns a relationship between input features and output variables. The training data is used to find patterns and relationships, which are then used to make predictions on new, unseen data. This approach is powerful because it allows for the creation of predictive models that can generalize to new data.
Unsupervised Learning Algorithms
Unsupervised learning algorithms work with unlabeled datasets, meaning that the data points do not have associated output variables. The algorithm's goal is to discover hidden patterns, structures, or relationships within the data. Clustering algorithms, like k-means, and dimensionality reduction techniques, like principal component analysis (PCA), are examples of unsupervised learning. These algorithms are valuable for tasks like customer segmentation, anomaly detection, and exploratory data analysis.
Unsupervised learning is useful for understanding the inherent structure of data without prior knowledge of the output variables. This lack of pre-defined labels allows the algorithm to discover hidden relationships and patterns that might be missed by supervised learning methods.
Reinforcement Learning Algorithms
Reinforcement learning is a distinct approach to machine learning where an agent learns to interact with an environment by taking actions and receiving rewards or penalties. The agent's goal is to maximize its cumulative reward over time. Examples include Q-learning and deep Q-networks (DQN). These algorithms are often used in robotics, game playing, and autonomous driving, where the agent needs to learn optimal strategies through trial and error.
The agent learns through trial and error, receiving feedback in the form of rewards or penalties for its actions. This feedback allows the agent to adjust its behavior and improve its performance over time, ultimately leading to optimal decision-making in the environment.
Deep Learning Algorithms
Deep learning algorithms are a subset of machine learning that use artificial neural networks with multiple layers to learn complex patterns and representations from data. These algorithms excel at tasks involving large amounts of data and complex relationships. Deep learning is particularly effective in image recognition, natural language processing, and speech recognition. Convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are popular examples of deep learning architectures.
Deep learning models can automatically learn hierarchical representations of data, progressing from low-level features to high-level concepts. This hierarchical learning allows the models to capture intricate patterns and relationships within the data, leading to improved accuracy and performance in various applications.
Ensemble Learning Algorithms
Ensemble learning techniques combine multiple individual learning models to create a more accurate and robust prediction model. By averaging the predictions of multiple models, ensemble methods often outperform individual models. Bagging and boosting are popular ensemble methods. These methods are particularly effective in improving the performance of classification and regression tasks.
Ensemble methods leverage the strengths of multiple models to mitigate the limitations of individual models. This approach often results in a more generalized and less prone-to-error model, which is crucial for complex and uncertain tasks.
Evaluating Machine Learning Models
Evaluating the performance of machine learning models is a critical step in the development process. Appropriate metrics must be chosen to assess the model's accuracy and generalization capabilities. Common metrics include precision, recall, F1-score, and area under the ROC curve (AUC). These metrics provide insights into the model's ability to correctly classify instances and its robustness in handling unseen data.
Different evaluation metrics are suited for different types of machine learning tasks and datasets. Careful consideration of the specific application and desired outcomes is essential when selecting appropriate evaluation methods. This allows for a more objective and complete assessment of the model's performance.
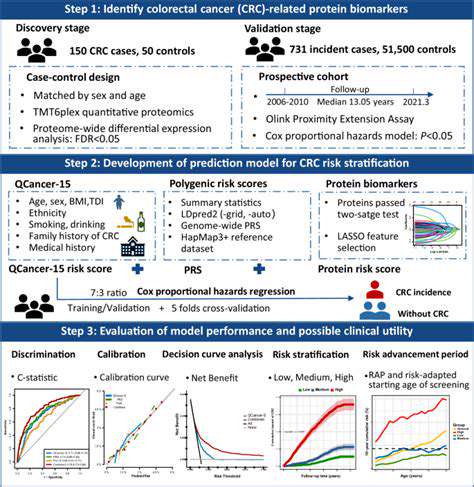
Challenges and Future Directions
Improving Accuracy and Reliability
One of the key challenges in utilizing AI for cardiac disease prognosis is ensuring the accuracy and reliability of the models. Current AI algorithms, while showing promise, are often trained on limited datasets, potentially leading to biases and inaccuracies in predictions. Furthermore, the complex interplay of genetic, environmental, and lifestyle factors influencing cardiac health necessitates the inclusion of diverse and comprehensive data sources in training datasets. Improving the quality and quantity of available data, incorporating external factors, and exploring more robust model architectures are crucial steps in enhancing the trustworthiness of AI-driven prognostic tools.
Another significant aspect of accuracy is the need for validation across diverse populations. AI models trained on a specific demographic may not perform optimally when applied to different ethnicities or age groups. Rigorous validation studies, encompassing various patient populations and clinical settings, are essential to ensure generalizability and applicability of AI-driven prognostic models in real-world clinical practice. This includes considering factors like socioeconomic status, access to healthcare, and adherence to treatment plans, which are often intertwined with the development and progression of cardiac conditions.
Addressing Ethical and Societal Implications
The integration of AI into cardiac disease prognosis raises important ethical and societal considerations. Ensuring equitable access to AI-powered tools for all patients, regardless of their socioeconomic background or geographic location, is paramount. Addressing potential biases within the data used to train these models is also crucial to minimize discrimination and ensure fair treatment for all individuals. Transparency and explainability of AI algorithms are essential to build trust among clinicians and patients, allowing them to understand how predictions are made and to question the reasoning behind the model's output.
Privacy concerns related to patient data used for training and deployment of AI models must be carefully considered and addressed. Robust data security measures and adherence to ethical guidelines for data handling and sharing are critical to protecting patient confidentiality and maintaining trust in the system. Furthermore, the potential impact on healthcare professionals' roles and responsibilities in the age of AI-driven diagnostics requires careful consideration and proactive strategies for workforce adaptation and training.
The potential for over-reliance on AI tools without considering the critical role of human judgment in the diagnostic process must also be acknowledged. Strategies for integrating AI outputs with clinical expertise and human oversight are essential to avoid potential errors or misinterpretations. Careful consideration of the long-term societal implications of AI in healthcare is crucial for ensuring responsible and beneficial implementation.
Careful consideration of the potential for AI to exacerbate existing healthcare inequalities, particularly in underserved populations, is vital. Initiatives to bridge the digital divide and ensure equitable access to AI-powered tools are necessary to prevent further marginalization.