Evaluating Anomaly Detection Models
Understanding the Different Types of Anomalies
Anomaly detection is a crucial aspect of data analysis, aiming to identify unusual patterns or data points that deviate significantly from the expected behavior. These anomalies can represent fraudulent transactions, equipment malfunctions, or unexpected market shifts. Understanding the different types of anomalies is fundamental to selecting the right detection model. Anomalies can be point anomalies, which are isolated data points that deviate from the norm, or contextual anomalies, which are patterns of data points that deviate from the expected behavior. Furthermore, anomalies can be classified as either global or local, depending on whether they deviate from the overall data distribution or from a specific subset of the data.
Different types of anomalies require different detection methods. For example, detecting a single unusual transaction in a financial dataset might necessitate a different approach than identifying a series of unusually low sensor readings from a manufacturing machine. Understanding the nature of the anomalies is key to building an effective and accurate model. Careful consideration of the specific characteristics and context of the data is crucial for choosing the most appropriate anomaly detection technique. By properly categorizing the anomalies, the model's accuracy and efficiency can be significantly improved.
Evaluating Model Performance Metrics
Evaluating the performance of an anomaly detection model is critical to ensure its effectiveness in real-world applications. Several metrics are used to assess the model's ability to accurately identify anomalies. Accuracy is a key metric, measuring the proportion of correctly classified instances, but it can be misleading when dealing with imbalanced datasets, where anomalies are significantly less frequent than normal instances. Precision and recall provide a more nuanced evaluation, focusing on the model's ability to correctly identify positive instances (anomalies) and the completeness of its detection. A high precision score indicates that the model is less likely to mislabel normal instances as anomalies. A high recall score signifies the model's ability to capture the majority of anomalies.
Precision, recall, and F1-score are commonly used metrics for evaluating the performance of anomaly detection models. These metrics provide insights into the model's ability to distinguish between anomalies and normal data points. However, the optimal choice of metrics depends on the specific application and the relative importance of precision and recall. For example, in fraud detection, a high recall is often prioritized to minimize the risk of missing fraudulent activities, even if it leads to some false positives. A balanced approach, using a combination of these metrics, often provides a more comprehensive evaluation.
Choosing the Right Anomaly Detection Algorithm
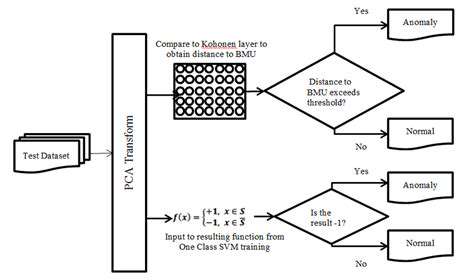
A variety of algorithms are available for anomaly detection, each with its strengths and weaknesses. Choosing the right algorithm depends on the characteristics of the data and the nature of the anomalies being sought. For example, statistical methods like the Isolation Forest algorithm are effective for identifying outliers in high-dimensional datasets. Machine learning approaches like one-class SVM are particularly useful when the normal data distribution is well-defined. Furthermore, ensemble methods can combine the strengths of multiple algorithms to improve overall detection accuracy. The optimal choice depends on the specific dataset and the goals of the analysis.
Understanding the strengths and weaknesses of different algorithms is crucial for effective model selection. Different algorithms excel in different situations, so carefully considering the type of data and the desired outcome is vital. For example, clustering algorithms excel at identifying groups of similar data points. Anomaly detection models that combine multiple algorithms can often outperform single-algorithm models. This combined approach leverages the strengths of diverse methodologies to provide more robust and accurate results.
Considering factors like computational cost and scalability is also important when selecting an algorithm. Some algorithms may require significant computational resources, making them unsuitable for large datasets or real-time applications. Therefore, selecting the right algorithm is a critical step in building a successful anomaly detection system. The chosen algorithm should be well-suited to the data, resources, and the specific needs of the application.
Challenges and Future Directions
Overcoming Technological Limitations
One significant challenge in advancing this field lies in overcoming the technological limitations that currently constrain our ability to fully harness the potential of innovative solutions. Many promising technologies are hindered by issues related to scalability, cost-effectiveness, and integration with existing infrastructure. Addressing these roadblocks is crucial for widespread adoption and meaningful impact. We need innovative solutions to these hurdles to ensure that these advancements can be implemented in a practical and effective manner.
Furthermore, the development of robust and reliable data collection methods, particularly in complex and dynamic environments, is essential. Significant investment in research and development is necessary to improve the accuracy and efficiency of data acquisition, paving the way for more reliable and impactful results.
Addressing Ethical Considerations
As these technologies advance, it is imperative to carefully consider the ethical implications. Issues like data privacy, algorithmic bias, and potential misuse of information require proactive solutions. We must establish clear ethical guidelines and robust regulatory frameworks to ensure responsible development and deployment. These considerations cannot be ignored, and ethical considerations must be prioritized throughout the research and implementation process.
Ensuring equitable access to these advancements is crucial. Disparities in access could exacerbate existing societal inequalities. Therefore, efforts must be made to ensure equitable access and benefits for all members of society, thereby mitigating potential harm.
Enhancing Interdisciplinary Collaboration
To effectively address the multifaceted challenges in this field, interdisciplinary collaboration is paramount. Bringing together expertise from diverse fields, including computer science, engineering, social sciences, and humanities, is critical to fostering innovation and ensuring that solutions are not only technologically sound but also socially relevant. Collaboration across disciplines will enable a broader perspective on the problems and facilitate the development of more comprehensive solutions.
This collaborative approach will allow for a more holistic understanding of the challenges and opportunities presented by these advancements.
Improving Data Security and Privacy
Data security and privacy are paramount concerns in the context of these advancements. Robust security measures are crucial to protect sensitive data from unauthorized access and breaches. Implementing and maintaining strong security protocols is essential to ensure the confidentiality and integrity of the information collected and processed.
Protecting user data and ensuring adherence to privacy regulations, such as GDPR, is vital. This requires ongoing vigilance and adaptive security measures to stay ahead of evolving threats.
Optimizing Resource Allocation and Funding
Efficient resource allocation and sustainable funding models are vital for long-term progress in this field. Strategic planning and investment in research and development are critical to fostering innovation and accelerating the pace of progress. Prioritizing funding for promising research initiatives is essential for realizing the full potential of these technologies.
Establishing clear funding mechanisms that support ongoing research and development initiatives is essential for long-term success.
Fostering Public Understanding and Acceptance
Building public understanding and acceptance of these technologies is crucial for successful implementation. Transparent communication and education initiatives can help to dispel myths and misconceptions and foster trust among the public. Effective communication strategies are necessary to ensure that the public understands the potential benefits and risks associated with these advancements.
Engaging with stakeholders, including the public, policymakers, and industry leaders, is essential for shaping responsible development and deployment strategies, creating a supportive environment for innovation.