Defining the Scope of Data Collection
Every data-driven initiative must begin by carefully outlining the parameters of data collection. This critical phase requires pinpointing exact variables and measurements necessary to address research inquiries or resolve specific business challenges. Establishing precise boundaries guarantees that gathered data remains pertinent while avoiding resource waste on extraneous information, thereby optimizing the dataset's utility. Clear scoping also facilitates targeted preprocessing, as subsequent steps can be customized to the unique attributes of the acquired data.
Teams should meticulously evaluate potential data origins, ranging from organizational databases and external interfaces to surveys and controlled experiments. Strategic planning during this phase helps define stringent benchmarks for data integrity and uniformity - fundamental requirements for producing trustworthy analytical outcomes.
Data Source Identification and Selection
Selecting appropriate data repositories forms the backbone of effective information gathering. This process necessitates rigorous assessment of available options including corporate data warehouses, third-party interfaces, open datasets, and crowdsourced content. Each repository presents distinct advantages and constraints requiring thoughtful evaluation.
Comprehending a dataset's provenance and inherent qualities proves indispensable when evaluating its dependability and alignment with project goals. Critical examination of structural format, quantity, and potential systematic distortions ensures chosen sources adequately support research parameters and anticipated discoveries.
Data Collection Methodology Design
Crafting a meticulous data acquisition framework safeguards information quality throughout the gathering process. This entails specifying exact protocols for data capture, alongside instrumentation and methodological approaches. Establishing unambiguous standards for information recording, authentication, and confirmation processes remains paramount for preserving precision and coherence.
The methodology must incorporate strategies for addressing potential inaccuracies or discrepancies during collection. Well-designed corrective measures enable prompt resolution of data quality concerns, substantially reducing their analytical impact.
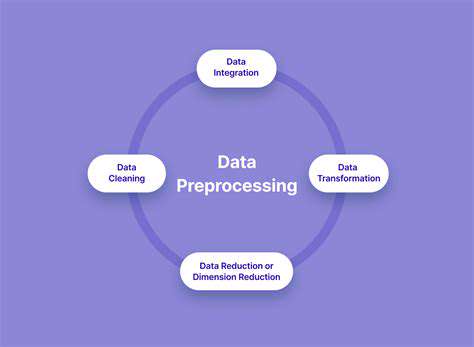
Data Cleaning and Transformation
Information purification and restructuring constitute vital preprocessing phases that condition datasets for meaningful examination. These procedures address absent measurements, anomalous entries, and internal contradictions within the data. Rectifying these complications proves essential for deriving valid, trustworthy conclusions from analytical efforts.
Restructuring techniques including normalization and standardization markedly enhance dataset quality for analytical purposes. Maintaining information consistency and accuracy across multiple sources prevents erroneous interpretations and false inferences.
Handling Missing Values
Addressing incomplete data represents a frequent preprocessing obstacle with significant analytical consequences. Various remediation strategies exist, ranging from basic mean/median substitution to advanced computational techniques.
Selection of appropriate gap-filling methods depends on the missing data's nature and the dataset's specific attributes. Deliberate evaluation of each approach's ramifications ensures analytical soundness and result dependability.
Outlier Detection and Treatment
Identifying and managing statistical anomalies constitutes another crucial preprocessing component. Extreme values can dramatically distort analytical outcomes. Detection methodologies incorporate both statistical testing and visual distribution analysis. The fundamental objective involves comprehending anomalous data origins before determining appropriate corrective actions to preserve analytical accuracy.
Automated outlier elimination risks discarding meaningful information, while ignoring distortions may produce misleading conclusions. Therefore, contextual evaluation of anomalies and their potential impact remains imperative.
Data Validation and Verification
Information authentication procedures serve as critical safeguards for dataset reliability. These processes examine data for precision, comprehensiveness, and internal consistency against established criteria. Thorough validation mechanisms significantly reduce inaccuracies while ensuring faithful representation of studied phenomena.
Implementing systematic quality assurance protocols maintains information integrity throughout project lifecycles. Regular inspections and controls facilitate early error detection and correction, guaranteeing analytical foundations remain robust.